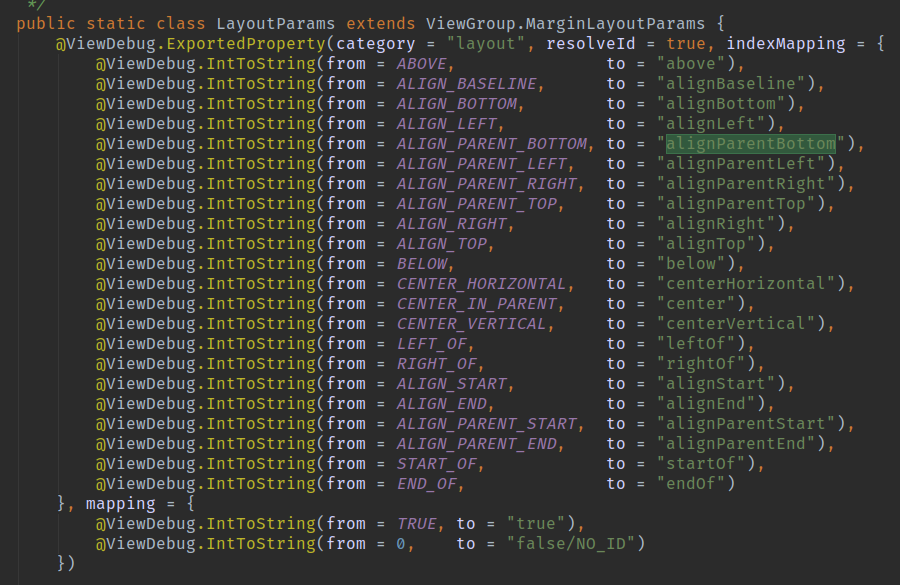
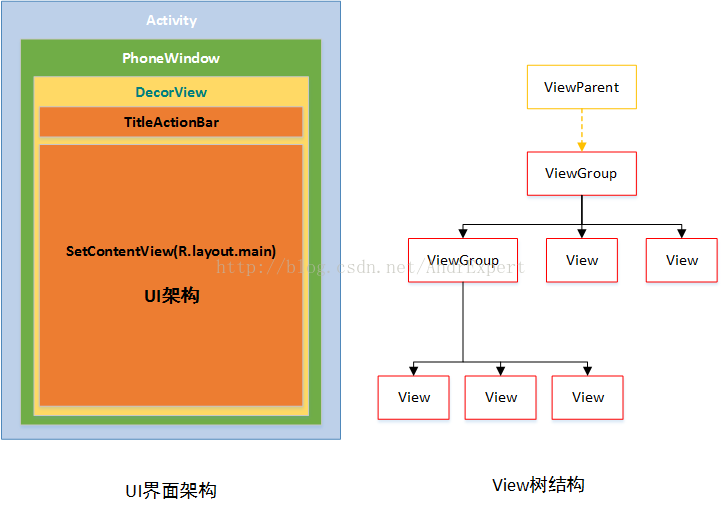
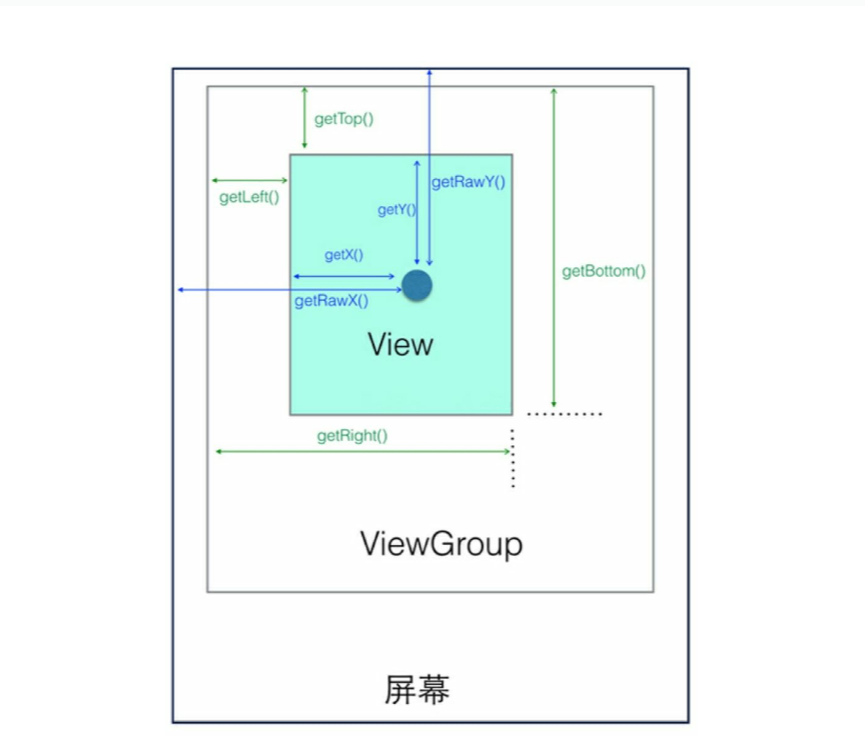
1、LayoutParams are used by views to tell their parents how they want to be laid out. LayoutParams是View用来告诉它的父控件如何放置自己的 2、The base LayoutParams class just describes how big the view wants to be for both width and height. 基类LayoutParams(也就是ViewGroup.LayoutParams)仅仅描述了这个View想要的宽度和高度 3、There are subclasses of LayoutParams for different subclasses of ViewGroup. 不同ViewGroup的继承类对应着不同的ViewGroup.LayoutParams的子类
List<Integer> list = new ArrayList<>(); list.add(5); list.add(23); list.add(42); for (int i = 0; i < list.size(); i++) { System.out.print(list.get(i) + ","); }
Iterator it = list.iterator(); while (it.hasNext()) { System.out.print(it.next() + ","); }
for (Integer i : list) { System.out.print(i + ","); }
不难发现java中也有stack直接实现类:Stack<T> stack = new Stack<>() 但是当你点进去看源码注释的时候发现:
A more complete and consistent set of LIFO stack operations isprovided by the {@link Deque} interface and its implementations, whichshould be used in preference to this class. For example: {@code Deque stack = new ArrayDeque();}
/** * Creates a new asynchronous task. This constructor must be invoked on the UI thread. * * @hide */ public AsyncTask(@Nullable Handler handler) { this(handler != null ? handler.getLooper() : null); }
/** * Creates a new asynchronous task. This constructor must be invoked on the UI thread. * * @hide */ public AsyncTask(@Nullable Looper callbackLooper) { mHandler = callbackLooper == null || callbackLooper == Looper.getMainLooper() ? getMainHandler() : new Handler(callbackLooper);
private static class InternalHandler extends Handler { public InternalHandler(Looper looper) { super(looper); }
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"}) @Override public void handleMessage(Message msg) { AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj; switch (msg.what) { case MESSAGE_POST_RESULT: // There is only one result result.mTask.finish(result.mData[0]); break; case MESSAGE_POST_PROGRESS: result.mTask.onProgressUpdate(result.mData); break; } } }
包装doInBackground方法。 创建完handle后,在第三个构造函数中可以看出,他接着创建了work(实现了callable)和futur(FutureTask对象其实就是更方便操作线程,Futrue可以监视目标线程调用call的情况,当你调用Future的get()方法以获得结果时,当前线程就开始阻塞,直接call方法结束返回结果。)其中很关键的代码就是在work中调用了,然后又将work用futuretask封装,在之后的调用中会最后提交给线程池 result = doInBackground(mParams); mFuture = new FutureTask<Result>(mWorker) {......}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
mWorker = new WorkerRunnable<Params, Result>() { public Result call() throws Exception { mTaskInvoked.set(true); Result result = null; try { Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND); //noinspection unchecked result = doInBackground(mParams); Binder.flushPendingCommands(); } catch (Throwable tr) { mCancelled.set(true); throw tr; } finally { postResult(result); } return result; } };
public void handleMessage(Message msg) { AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj; switch (msg.what) { case MESSAGE_POST_RESULT: // There is only one result result.mTask.finish(result.mData[0]); break; case MESSAGE_POST_PROGRESS: result.mTask.onProgressUpdate(result.mData); break; } }
protected final void publishProgress(Progress... values) { if (!isCancelled()) { getHandler().obtainMessage(MESSAGE_POST_PROGRESS, new AsyncTaskResult<Progress>(this, values)).sendToTarget(); } }
public final AsyncTask<Params, Progress, Result> executeOnExecutor(Executor exec, Params... params) { if (mStatus != Status.PENDING) { switch (mStatus) { case RUNNING: throw new IllegalStateException("Cannot execute task:" + " the task is already running."); case FINISHED: throw new IllegalStateException("Cannot execute task:" + " the task has already been executed " + "(a task can be executed only once)"); } }
if (mStatus != Status.PENDING) { switch (mStatus) { case RUNNING: throw new IllegalStateException(“Cannot execute task:” + “ the task is already running.”); case FINISHED: throw new IllegalStateException(“Cannot execute task:” + “ the task has already been executed “ + “(a task can be executed only once)”); } }
第三个 public View(Context context, AttributeSet attrs, int defStyleAttrs) 这个比第二个多出了一个defStyleAttrs,顾名思义,这是一个style,获取当前主题中声明的这个自定义view的style,所以,同个它可以实现不同主题有不同的显示效果。 这个构造函数通常是通过第二个构造函数调用,如:
public CircleView(Context context, @Nullable AttributeSet attrs) { this(context,attrs, R.attr.SimpleCircleStyle); }
同时通过其注释:
@param defStyleAttr An attribute in the current theme that contains a reference to a style resource that supplies default values for the view. Can be 0 to not look for defaults.
if (actionMasked == MotionEvent.ACTION_DOWN || mFirstTouchTarget != null) { final boolean disallowIntercept = (mGroupFlags & FLAG_DISALLOW_INTERCEPT) != 0; if (!disallowIntercept) { intercepted = onInterceptTouchEvent(ev); ev.setAction(action); // restore action in case it was changed } else { intercepted = false; } } else { // There are no touch targets and this action is not an initial down // so this view group continues to intercept touches. intercepted = true; }
.fullImageSampleSamplSize由private int calculateInSampleSize(float scale)计算出,这个值应该是我们首先应该理解的。 他决定了图片是否需要用BitmapRegionDecoder进行区域加载。如果他的计算结果等于1,则表示这张图的分辨率还不够大,不需要进行切割进行区域加载,所以这种情况下是最简单的,直接将图加载进入,放大缩小,移动,都是通过Matrix来实现的,所以接下来就来说一下Matrix
.fullImageSampleSamplSize由private int calculateInSampleSize(float scale)计算出,这个值应该是我们首先应该理解的。 他决定了图片是否需要用BitmapRegionDecoder进行区域加载。如果他的计算结果等于1,则表示这张图的分辨率还不够大,不需要进行切割进行区域加载,所以这种情况下是最简单的,直接将图加载进入,放大缩小,移动,都是通过Matrix来实现的,所以接下来就来说一下Matrix